هوش محاسباتی در
خودروهای خودران
تعاریف و ارکان اصلی
- تعریف: مجموعهای از الگوریتمهای هوشمند با الهام از طبیعت (یادگیری ماشین، منطق فازی، تکامل).
- هدف اصلی: جایگزینی راننده انسان با یک سیستم هوشمند و تصمیمگیرنده.
- دو رکن اساسی:
- ۱. ناوبری (Navigation): تشخیص موقعیت و برنامهریزی مسیر (نقشهخوانی).
- ۲. کنترل (Control): اجرای فرامین حرکتی (گاز، ترمز و فرمان).

سطوح خودمختاری و محیط آشوبناک
- استاندارد SAE (سطوح ۰ تا ۵): حرکت از «کمک راننده» (مثل کروز کنترل) به سمت «حذف راننده» (سطح ۵).
- تفاوت محیط کارخانه با خیابان:
- محیط کارخانه: قابل پیشبینی، تکراری و ایستا (قابل کدنویسی ساده).
- محیط خیابان: پر از عدم قطعیت، تغییرات لحظهای و رفتار غیرمنطقی دیگران.
- نتیجه: برای محیط پویا، به «هوش تطبیقپذیر» نیاز داریم، نه دستورات خشک.

چالش: چرا کدنویسی معمولی جواب نمیدهد؟
بنبست برنامهنویسی سنتی (Rule-Based)
- ۱. مشکل تعداد حالات بینهایت: غیرممکن بودن نوشتن دستور If-Then برای تمام اتفاقات خیابان.
- ۲. ناتوانی در تعمیم دادن (Generalization): کد معمولی اگر چیزی را قبلاً ندیده باشد، نمیداند چه واکنشی نشان دهد.
- ۳. عدم مدیریت ابهام: نویز سنسورها و شرایط آبوهوایی بد کدهای خطی را مختل میکند.

معماری سیستم: تفکیک وظایف
استراتژی «تقسیم و غلبه» (Divide and Conquer): شکستن مسئله بزرگ رانندگی به دو مسئله کوچکتر.
۱. مسیریابی سراسری (Global)
نگاه کلان (Macro):
یافتن مسیر بهینه روی نقشه (از مبدأ تا مقصد).
ورودی: نقشه شهر + GPS
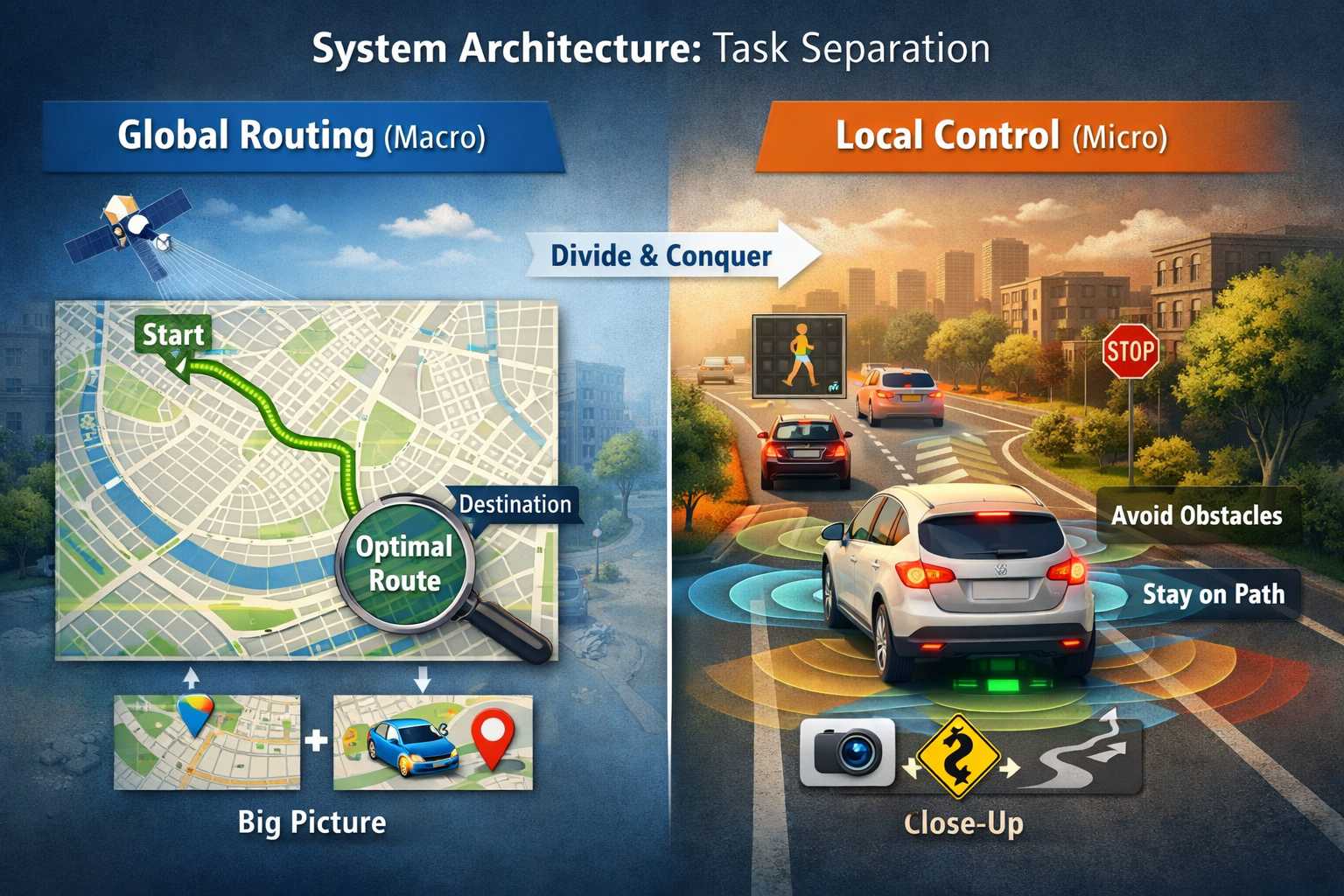
ارتباط بین برنامه ریزی کلان و کنترل خرد
۲. کنترل محلی (Local)
نگاه خرد (Micro):
تعقیب مسیر تعیین شده و اجتناب از برخورد لحظهای.
ورودی: سنسورها + مسیر سراسری
چالش اعتماد: کدام سنسور راست میگوید؟
مشکل: وجود نویز و قطع و وصل شدن سنسورها (مثل خطای GPS در تونل).
راه حل: فیلتر کالمن (Kalman Filter)
New_Estimate = Prediction + K × (Measurement - Prediction)
- K (Kalman Gain): ضریب اعتماد؛ وزنی که به سنسور در مقابل محاسبات فیزیکی داده میشود.
- تلفیق هوشمند دادهها (Sensor Fusion) برای حذف پرشهای ناگهانی.
- تخمین دقیق موقعیت (Position Estimation).
- نتیجه: تحویل دادههای «تمیز» به بخشهای مسیریابی و کنترل.
مدلسازی محیط: آمادهسازی زمین بازی
نیاز مسئله: تبدیل دادههای خام سنسورها به نقشهای قابل فهم برای الگوریتم.
نقشه شبکهای (Occupancy Grid Map)
- تقسیم محیط به سلولهای کوچک مربعی (پیکسلها).
- ● سلول سیاه (۱): نشاندهنده وجود مانع.
- ● سلول سفید (۰): نشاندهنده فضای آزاد.
- خروجی: یک ماتریس ریاضی که به عنوان «فضای جستجو» به الگوریتم PSO داده میشود.

تبدیل دنیای واقعی به ماتریس صفر و یک
معماری ترکیبی: انتخاب بهترین ابزار
- ۱. الگوریتم PSO (بهینهسازی ذرات):
نقش: مسیریاب سراسری (جستجوی سریع مسیر روی نقشه). - ۲. سیستم ANFIS (فازی-عصبی):
نقش: کنترلکننده فرمان و سرعت (رانندگی نرم با ترکیب تجربه و منطق). - ۳. الگوریتم DRL (یادگیری تقویتی):
نقش: سیستم ایمنی و اجتناب از موانع پویا در لحظات بحرانی.
الگوریتم PSO: هوش جمعی در مسیریابی
مفهوم ذرات (Particles): رها کردن تعداد زیادی راننده خیالی برای یافتن بهترین مسیر.
معادله حرکت ذرات:
- ۱. اینرسی: تمایل به ادامه مسیر قبلی.
- ۲. حافظه فردی (P-Best): حرکت به سمت بهترین تجربه شخصی.
- ۳. خرد جمعی (G-Best): حرکت به سمت بهترین مسیر کل گروه.

همگرایی ذرات روی مسیر بهینه
سیستم ANFIS: کنترلری با دو نیمکره مغز
یک سیستم هیبریدی که مزایای «منطق فازی» و «شبکههای عصبی» را یکجا دارد.
چرا ANFIS؟
- منطق فازی: درک مفاهیم انسانی (مثل انحراف کم/زیاد).
- شبکه عصبی: یادگیری و تنظیم خودکار برای کاهش خطا.
نتایج عملکرد:
- ورودی: خطای فاصله + خطای زاویه.
- خروجی: زاویه دقیق فرمان.
- نتیجه: رانندگی نرم (Smooth) و بدون زیگزاگ.

تلفیق هوش بیولوژیک و دقت محاسباتی برای حذف لرزشهای فرمان
یادگیری تقویتی (DRL) و ایمنی
- الگوریتم DRL: یادگیری از طریق آزمون و خطا (پاداش برای حرکت امن، تنبیه برای تصادف).
- کاربرد: واکنش سریع به موانع متحرک (مثل عابر پیاده).
در ادامه به بررسی دقیقتر چالشهای دنیای واقعی و اثبات ریاضی پایداری میپردازیم...

چرا رانندگی در دنیای واقعی سختتر است؟
فراتر از شبیهسازی: چالشهای پیشبینی نشده
- ۱. محدودیتهای محیطی (کوری سنسورها):
اختلال شدید LiDAR در باران، مه و گرد و خاک. پنهان شدن خطکشیها زیر برف. - ۲. تهدیدات امنیتی (Security):
- هک سیستم: خطر دسترسی غیرمجاز به ترمز و فرمان.
- حملات فریبنده (Adversarial): گول زدن هوش مصنوعی با چسباندن یک برچسب ساده روی تابلو (مثلاً دیدن تابلوی ایست به عنوان حداکثر سرعت).

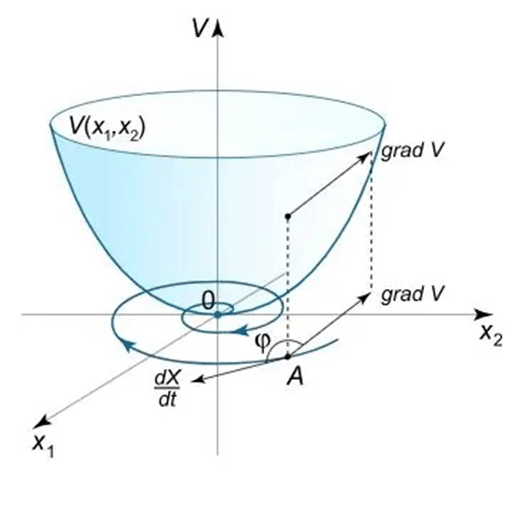
آیا هوش مصنوعی قابل اعتماد است؟ (اثبات ریاضی)
- هدف: اثبات اینکه خودرو هرگز از کنترل خارج نمیشود.
- روش: تئوری پایداری لیاپانوف (Lyapunov Stability).
- منطق اثبات (مثال توپ و کاسه):
- تعریف تابع انرژی (V): میزان «خطای سیستم» (همیشه مثبت).
- شرط پایداری: مشتق انرژی باید منفی باشد.
- نتیجه: انرژی خطا دائماً کاهش مییابد و سیستم به سمت پایداری کامل میل میکند.
جنگ تکنولوژی: PID در برابر هوش مصنوعی
مقایسه کنترلکننده کلاسیک با روش پیشنهادی (ANFIS)
| ویژگی | کنترل کلاسیک (PID) | کنترل هوشمند (ANFIS) |
|---|---|---|
| انعطافپذیری | نیاز به تنظیم دستی مجدد | تطبیق خودکار با جاده |
| مدیریت سیستم | فقط شرایط ساده و خطی | عالی در شرایط پیچیده (لغزش) |
| کیفیت رانندگی | دارای نوسان و پرش (Overshoot) | حرکت نرم و واکنش سریع |
| نتیجه نهایی | پایداری محدود | ایمنی و پایداری بالا |
به سوی آینده: خودروهای متصل (V2X)
- دستاورد ما: ارائه معماری ترکیبی (PSO + ANFIS + DRL) با تضمین پایداری ریاضی.
- آینده: اینترنت اشیاء در خودروها (V2X):
- V2V (خودرو با خودرو): تبادل اطلاعات ترمز و شتاب برای جلوگیری از تصادف زنجیرهای.
- V2I (خودرو با زیرساخت): هماهنگی با چراغ قرمز و تابلوهای هوشمند.
- هدف نهایی: رسیدن به سطح ۵ خودمختاری و ترافیک بدون تصادف.
منابع و مراجع (References)
با تشکر از توجه شما
پایان ارائه